배치방식으로 데이터 처리하기 (KMeansExample)
KMeans 클러스터링을 수행하는 배치데이터 처리 예제를 설명합니다.
입력 데이터 준비하기
본 예제에서는 Host PC의 /home/csle/ksb-csle/examples/input 폴더에 존재하는 input_kmeans.csv 파일을 사용자 HDFS repository에 등록하여 사용합니다. KSB 웹툴킷 상단의 Repository 메뉴를 클릭하여 데이터 저장소 관리화면으로 이동합니다. 파일을 업로드할 폴더(dataset/input)에서 File Upload 버튼을 클릭하여 input_kmeans.csv 파일을 업로드 합니다. 이 때 입력파일을 설명하는 이름(Name)과 설명(Description)을 함께 입력할 수 있습니다.
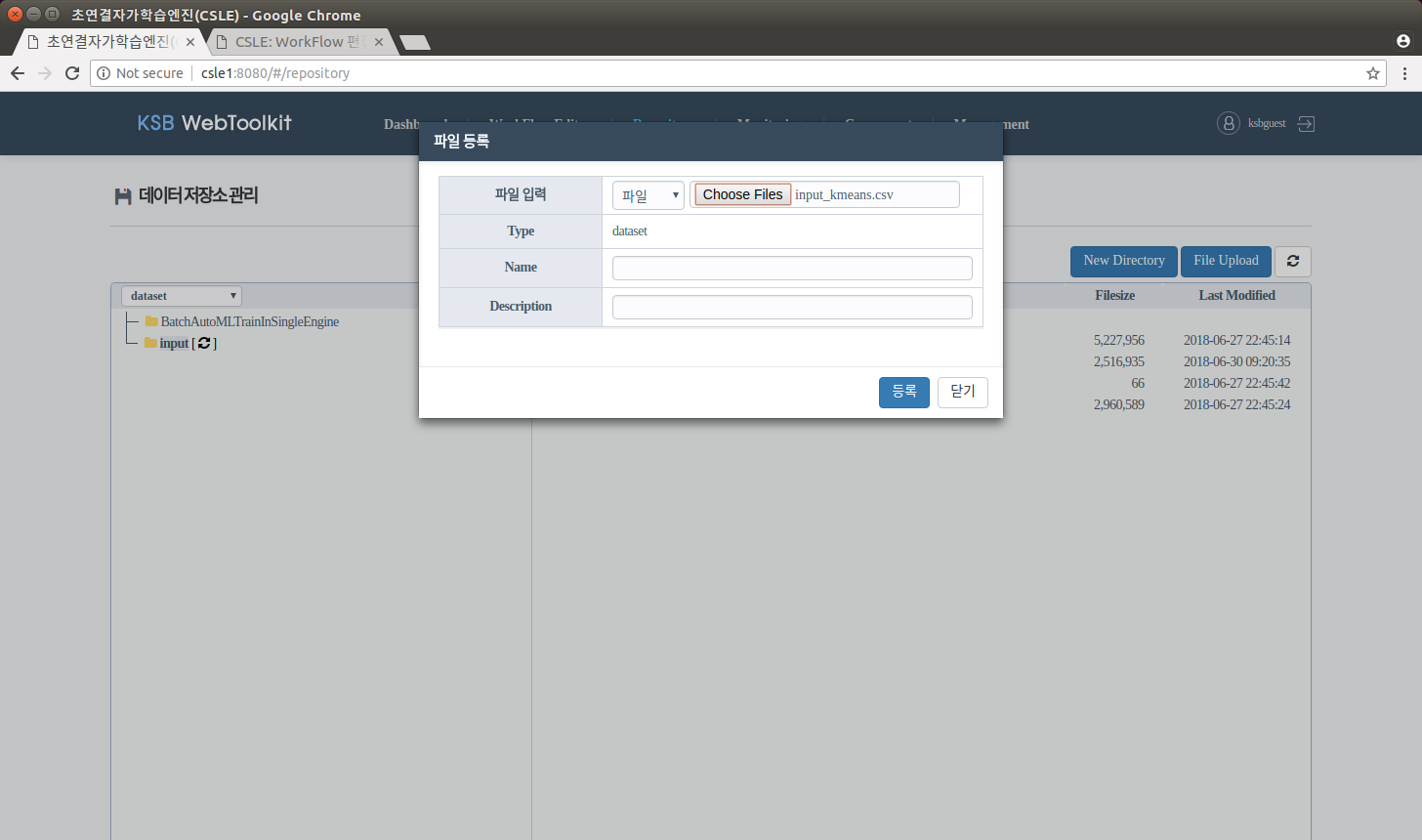
dataset/input 폴더에 파일이 업로드 된 것을 확인할 수 있습니다. 최상위 폴더는 콤보박스로 선택하여 이동할 수 있습니다.
워크플로우 생성하기
워크플로우 편집화면을 이용하여 아래의 과정을 통해 워크플로우를 생성합니다.
- 워크플로우 속성
| 속성 | 값 | 비고 |
|---|---|---|
| name | KMeansExample | 워크플로우 이름 |
| description | KMeans 클러스터링을 수행하는 배치데이터 처리 예제 | 워크플로우를 설명하는 글 |
| isBatch | true | 배치 처리를 하는 워크플로우 이므로, true 로 지정 |
| verbose | false | 디버깅을 위해 로그정보를 보고자할 경우, true 로 지정 |
엔진 선택
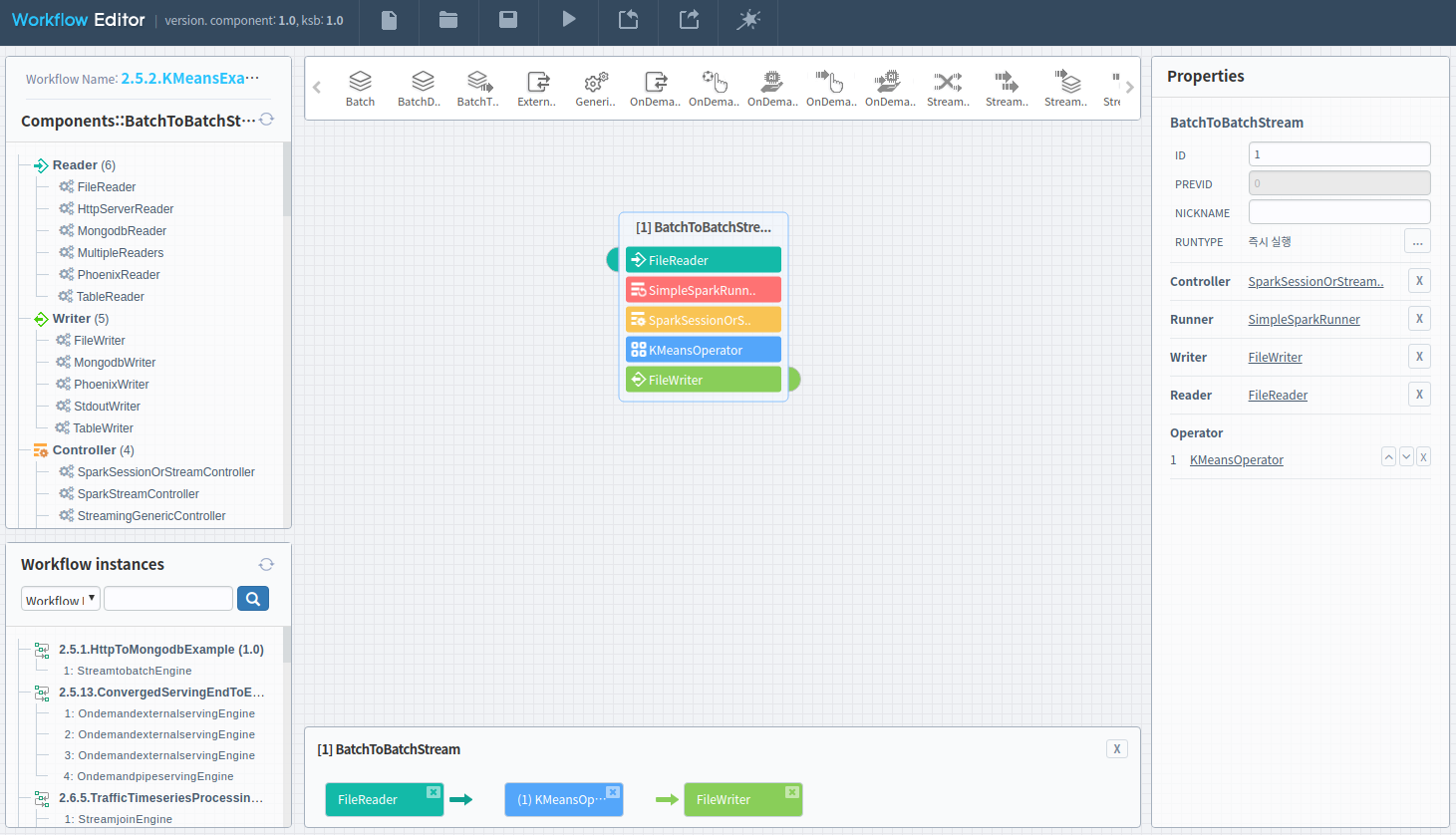
KSB 인공지능 프레임워크 저장소에 등록된 파일을 입력 받아 전처리를 수행한 후 로컬 파일에 저장하기 위해 BatchToBatchStream 엔진을 드래그앤 드롭합니다.
- 엔진 속성
| 순번 | 엔진 Type | NickName | RunType | 설명 |
|---|---|---|---|---|
| 1 | BatchToBatchStream | ProcessingEngine | 즉시실행 | KMeans 클러스터링 수행 |
Reader
KSB 인공지능 프레임워크 데이터 저장소에 등록된 파일을 읽기 위해 FileReader 를 드래그 앤 드롭한 후 아래표와 같은 속성을 지정합니다.
| field | value | 설명 |
|---|---|---|
| filePath | dataset/input/input_kmeans.csv | 입력 파일 경로 |
| fileType | CSV | 입력 파일 타입 |
| delimiter | , | 구분자 |
| header | false | header 포함 유무 |
| filed | DATA1 / DOUBLE DATA2 / DOUBLE DATA3 / INTEGER DATA4 / DOUBLE DATA5 / DOUBLE |
파일에서 읽을 칼럼(key)과 타입(type) |
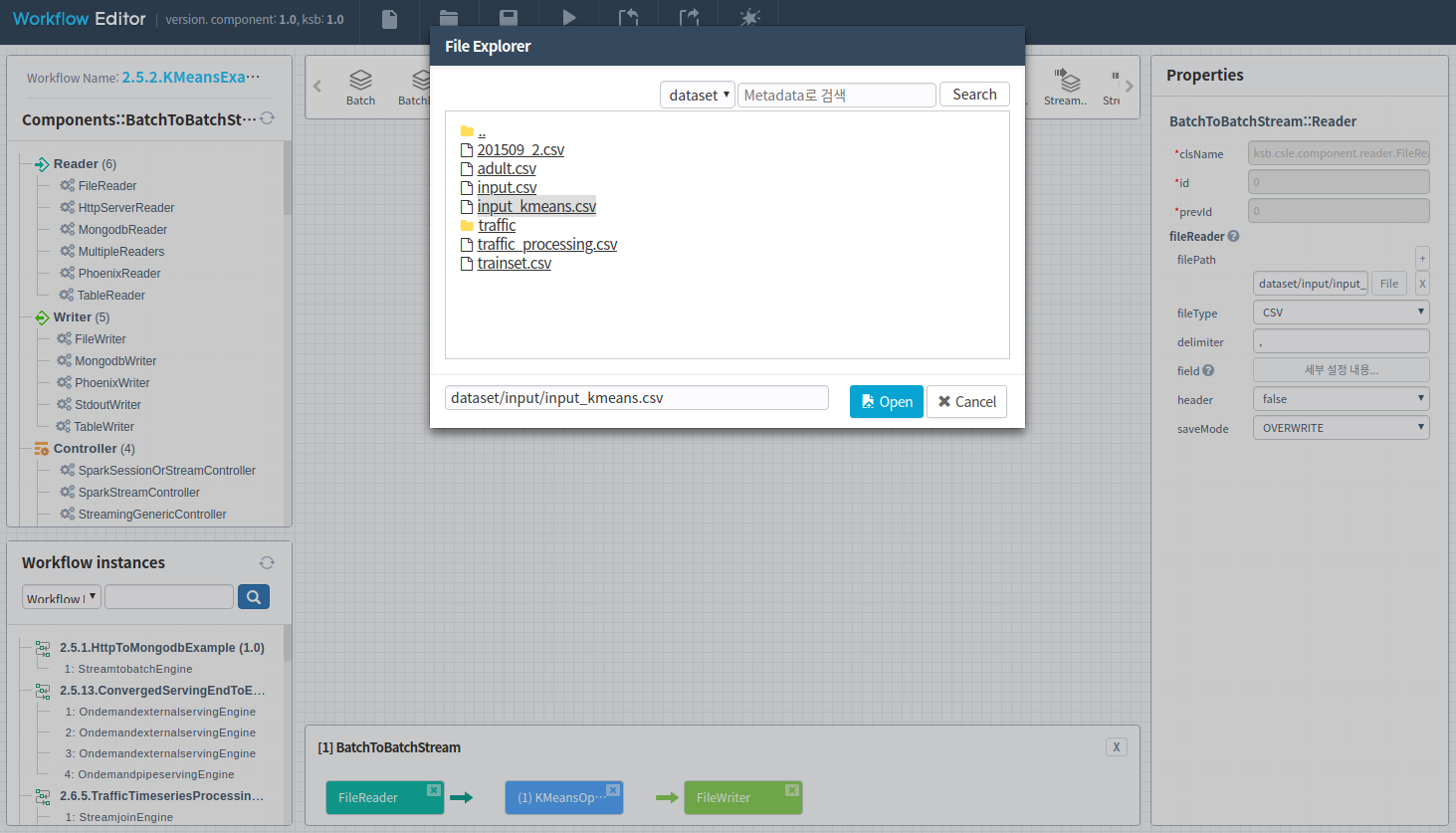
- filePath 입력방법
File 버튼을 클릭하여 사용자 HDFS repository에 등록된 파일을 선택합니다.
Writer
FileWriter 를 드래그 앤 드롭한 후 아래표와 같은 속성을 지정합니다.
| field | value | 설명 |
|---|---|---|
| filePath | output/result_kmeans | 저장 파일 경로 |
| fileType | CSV | 저장 파일 타입 |
| delimiter | , | 구분자 |
| header | false | header 포함 유무 |
| saveMode | OVERWRITE | 파일 저장 방식 |
Controller
SparkSessionOrStreamController 를 선택합니다.
SparkSessionOrStreamController 는 Spark 환경에서 배치 처리나 스트림 처리에 범용적으로 사용하는 컨트롤러입니다.
| field | value | 설명 |
|---|---|---|
| operationPeriod | 0 | 컨트롤러 실행 주기. 배치처리일 경우, 0. stream 처리의 경우, 실행 주기값 (초단위). |
Runner
SimpleSparkRunner 를 선택한 후 디폴트 속성값을 사용합니다.
| field | value | 설명 |
|---|---|---|
| master | local [ * ] | Spark 모드. |
| executerMemory | 1g | Spark의 executor 메모리 |
| totalCores | 2 | Spark 전체 할당 가능 코어수 |
| cores | 2 | Spark 현재 할당 코어수 |
| numExecutors | 2 | Spark의 executor 갯수 |
| sparkVersion | 2.3.0 | Spark 버전 정보 |
| driverMemory | 1g | Spark 드라이버에 할당할 메모리 정보 |
Operator
KMeans 클러스터링을 수행하기 위하여 KMeansOperator 를 선택한 후 아래표와 같은 속성을 지정합니다.
| field | value | 설명 |
|---|---|---|
| k_value | 2 | 클러스터 개수 |
| maxIterations | 100 | 최대 반복 회수 |
| maxRuns | 1 |
ksbuser@etri.re.kr 계정으로 접속하면 예제 워크플로우가 KMeansExample 이름으로 저장되어 있으며, 워크플로우를 불러올 수 있습니다.
워크플로우 실행 및 모니터링하기
워크플로우 실행하기
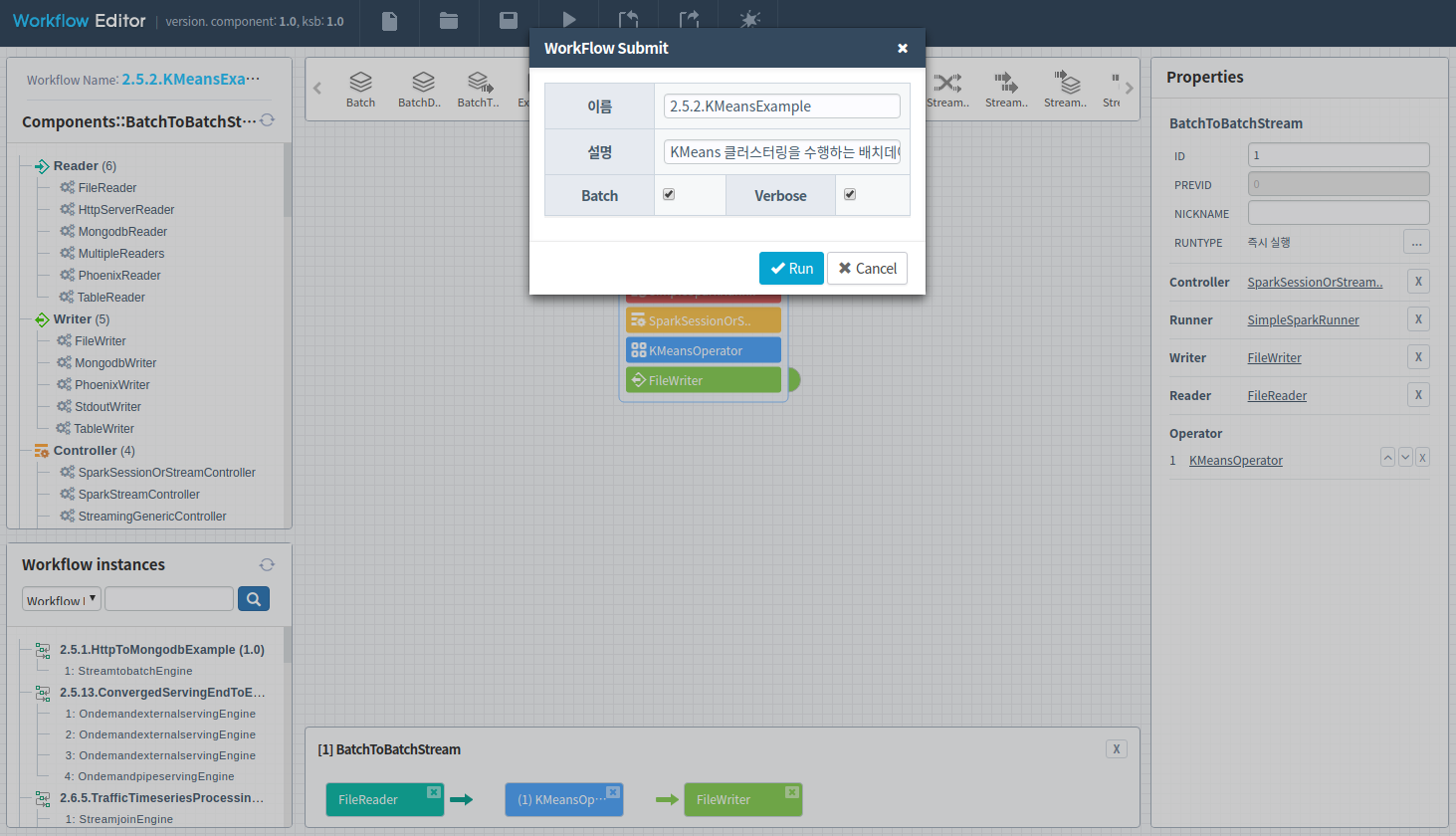
위에서 작성한 워크플로우를 실행하기 위해서는 워크플로우 편집기 상단의 실행 버튼(▶)을 클릭합니다. 본 예제는 배치형태로 실행되는 엔진을 사용하였으므로 Batch 체크 박스를 체크하고 워크플로우를 실행합니다.
워크플로우 모니터링 하기
워크플로우 상태 확인
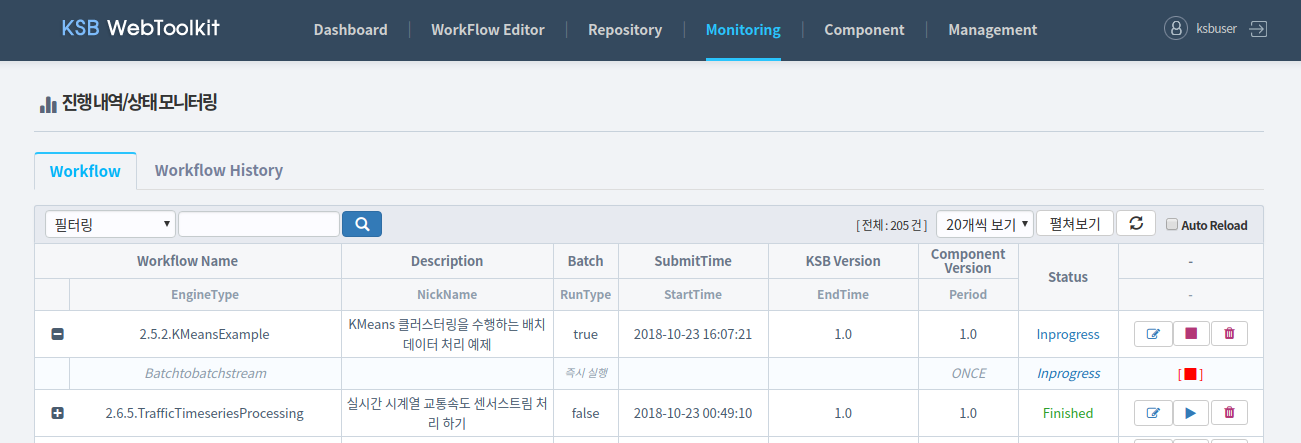
KSB 웹툴킷 상단의 Monitoring 메뉴를 클릭하여 진행내역/상태모니터링 화면으로 이동합니다. Workflow 탭에서 작성한 워크플로우 및 각 엔진의 상태를 확인할 수 있습니다. 또한 실행 중인 워크플로우를 종료(◼)하거나, 다시 실행(▶)할 수 있습니다.
결과 확인하기
KSB 웹툴킷 데이터 저장소 관리 메뉴에서 해당 폴더에 결과 파일이 생성된 것을 확인 할 수 있습니다.