- 주변 데이터들의 밀도를 이용하여 군집을 생성해 나가는 방식이다.
- 밀도가 높은 지역에 있는 data points는 cluster에 할당하고 밀도가 낮은 지역에 있는 data points는 outlier points(noise points)로 본다.
- 아래 그림의 경우 최소 포인트가 6일 경우 클러스터 할당 모습이다. Epsilon 만큼 범위를 확대해 나가고 있다.
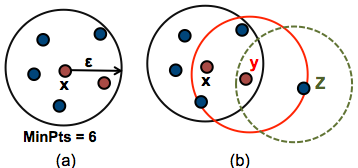
- 클러스터에 할당하기 위한 최소 조건이 min point가 6이상이어야 한다
하지만 z는 이웃이 5개, 2개 이므로 noise 포인트가 된다.
- eps: core point로부터 cluster 테두리까지의 반경이며 이웃들의 크기를 정의 (required)
- minPts: eps 거리 내에 있어야만 하는 최소 데이터의 개수 (required)
- 입력 DataFrame의 유효성 검사를 진행한다. (Epsilon, min point, Numeric Columns)
- 변수 초기화를 한다. (visitList, noistList, clusterMap)
- Row 데이터의 이웃하는 목록을 가져온다.
- 이웃하는 목록 리스트로 또 다시 이웃하는 목록 리스트를 구해온다. 방문기록을 남긴다.
- 결과를 클러스터에 할당하거나 noise 기록을 한다
- 모든 방문 기록이 완료 될 때까지 3 ~ 5 과정을 반복한다.
- 출력 DataFrame을 생성한다.
| index |
data1 |
data2 |
| 1 |
6.848934849 |
3.158069218 |
| 2 |
-0.943968337 |
22.91433149 |
| 3 |
-1.175376171 |
23.9929549 |
| 4 |
-0.728804819 |
23.59998941 |
| 5 |
-0.554106973 |
23.14728525 |
| 6 |
-0.50858251 |
23.55578863 |
| 7 |
-0.655966008 |
24.12991918 |
| 8 |
-0.828753893 |
23.06295102 |
| 9 |
-0.906446078 |
23.63442066 |
| 10 |
-1.175471759 |
23.23088862 |
| 11 |
-0.586424383 |
23.56802483 |
| 12 |
6.029774804 |
3.337247273 |
| 13 |
-1.022162431 |
23.21138139 |
| 14 |
-0.665984656 |
23.20667453 |
| 15 |
-0.578946901 |
23.40512492 |
| 16 |
-0.45042623 |
23.88963325 |
| 17 |
-0.639808699 |
23.55207991 |
| 18 |
-0.971141606 |
23.10933188 |
| 19 |
-0.866241774 |
22.74841298 |
| index |
data1 |
data2 |
CLUSTER |
| 1 |
6.848934849 |
3.158069218 |
0 |
| 2 |
-0.943968337 |
22.91433149 |
1 |
| 3 |
-1.175376171 |
23.9929549 |
0 |
| 4 |
-0.728804819 |
23.59998941 |
1 |
| 5 |
-0.554106973 |
23.14728525 |
1 |
| 6 |
-0.50858251 |
23.55578863 |
1 |
| 7 |
-0.655966008 |
24.12991918 |
0 |
| 8 |
-0.828753893 |
23.06295102 |
1 |
| 9 |
-0.906446078 |
23.63442066 |
1 |
| 10 |
-1.175471759 |
23.23088862 |
1 |
| 11 |
-0.586424383 |
23.56802483 |
1 |
| 12 |
6.029774804 |
3.337247273 |
0 |
| 13 |
-1.022162431 |
23.21138139 |
1 |
| 14 |
-0.665984656 |
23.20667453 |
1 |
| 15 |
-0.578946901 |
23.40512492 |
1 |
| 16 |
-0.45042623 |
23.88963325 |
1 |
| 17 |
-0.639808699 |
23.55207991 |
1 |
| 18 |
-0.971141606 |
23.10933188 |
1 |
| 19 |
-0.866241774 |
22.74841298 |
1 |
- 결과 데이터의 CLUSTER column에서 각 data들이 할당된 cluster를 보여준다.
- DBSCAN Operator에 의해 data들이 2개의 cluster에 할당 되었음을 알 수 있다.
- parameter는 다음과 같이 설정하였다.
val dBSCANInfo =
DBSCANInfo.newBuilder()
.setEps(0.5)
.setMinPts(5)
.build