- 한번에 하나씩의 설명변수를 사용하여 예측 가능한 규칙들의 집합을 생성하는 알고리즘이다.
- 입력한 데이터 중 DecisionTree의 결과를 토대로 주요한 column을 추출하는 기능이다.
wikipedia,2018년8월20일,https://ko.wikipedia.org/wiki/결정_트리_학습법
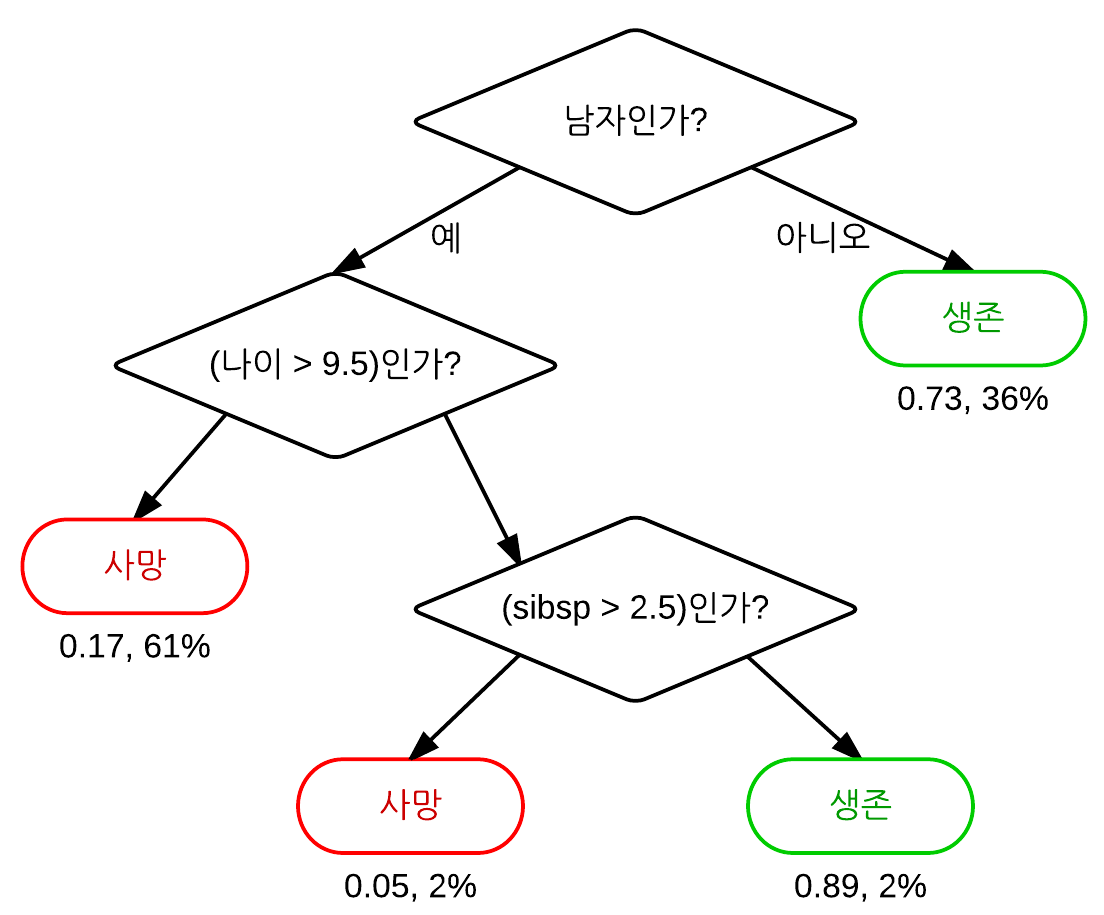
- 위의 DecisionTree는 타이타닉호 탑승객의 생존 여부를 나타내는 DecisionTree이다. (“sibsp”는 탑승한 배우자와 자녀의 수를 의미한다.) leaf node 아래의 숫자는 각각 생존 확률과 탑승객이 그 leaf node에 해당될 확률을 의미한다.
- labelName: 라벨 이름 (required)
- maxDepth: Tree node의 최대 깊이 (required)
- minInfoGain: Tree node를 분할 하기 위해 필요한 최소의 정보 획득(순도 증가/불순도 감소=정보획득) (required)
- maxBins: Tree 최대 Bin 개수 (required)
- cacheNodeIds: cache 노드 Ids (required)
- max depth의 값이 클 경우(deep trees) cacheNodeIds를 True로 설정하여 성능을 향상시킬 수 있다.
- checkpointInterval: 체크포인트 간격. Checkpoint interval(>= 1) or disable checkpoint(-1) (required)
- impurityType: 불순도 지표. Enum(GINI, ENTROPY) (required)
- 입력 DataFrame의 유효성 검사를 진행한다. (Label Column)
- 문자 칼럼을 숫자 칼럼으로 바꾸는 작업을 한다. (index_trasformers)
- 모든 데이터를 Vectors로 변환 후 feature 칼럼으로 생성한다. (assembler)
- labelIndexer에 라벨 이름을 설정한다.
- Spark ml의 DecisionTreeClassifier 알고리즘을 설정한다. (Max Depth, gain, impurity 등) - dt
- IndexToString을 사용하여 나온 예측 결과를 다시 문자로 변환한다. (labelConverter)
- index_transformers, assembler, labelIndexer, dt, labelConverter를 stage로 설정한 후 Pipeline을 사용하여 모델링한다.
- Dt를 DecisionTreeClassificationModel로 변환하여 featureImportances를 확인한다.
- fetureImportances가 0이 아닐 경우에 출력 DataFrame에 포함 되어 생성한다.
| play |
outlook |
temperature |
humidity |
wind |
| no |
sunny |
85 |
85 |
false |
| no |
sunny |
80 |
90 |
true |
| yes |
overcast |
83 |
78 |
false |
| yes |
rain |
70 |
96 |
false |
| yes |
rain |
68 |
80 |
false |
| no |
rain |
65 |
70 |
true |
| yes |
overcast |
64 |
65 |
true |
| no |
sunny |
72 |
95 |
false |
| yes |
sunny |
69 |
70 |
false |
| yes |
rain |
75 |
80 |
false |
| yes |
sunny |
75 |
70 |
true |
| yes |
overcast |
72 |
90 |
true |
| yes |
overcast |
81 |
75 |
false |
| no |
rain |
71 |
80 |
true |
| outlook |
temperature |
wind |
| sunny |
85 |
false |
| sunny |
80 |
true |
| overcast |
83 |
false |
| rain |
70 |
false |
| rain |
68 |
false |
| rain |
65 |
true |
| overcast |
64 |
true |
| sunny |
72 |
false |
| sunny |
69 |
false |
| rain |
75 |
false |
| sunny |
75 |
true |
| overcast |
72 |
true |
| overcast |
81 |
false |
| rain |
71 |
true |
- 구현된 DecisionTreeInduction은 칼럼의 중요도에 따라 결과물을 뽑아내게 된다. (중요도가 0인경우 제외)
- DecisionTree의 column 중요도는 다음과 같다.
| featureImportances |
| outlook:0.495348837209302 |
| temperature:0.3052325581395349 |
| wind:0.199418604651163 |
- 중요도를 추출한 결과 Outlook > Temperature > Wind 순서이고 나머지 속성 column은 중요도가 0이므로 결과 DataFrame에 출력이 되지 않았다.