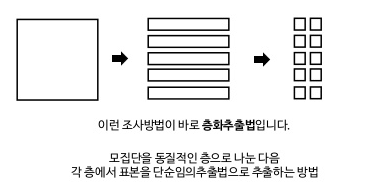
- 모집단을 먼저 중복되지 않도록 층으로 나눈 다음 각 층에서 표본을 추출하는 방법이다. 층을 나눌 때 층내는 동질적, 층간은 이질적 특성을 가지도록 하면 적은 비용으로 더 정확한 추정을 할 수 있으며, 전체 모집단뿐만 아니라 각 층의 특성에 대한 추정도 할 수 있다는 장점이 있다.
slideshare,2018년8월20일,https://www.slideshare.net/Newsjelly/1-50965379
- selectedColumnId: 선택할 column ID (required)
- fractions: sample 사이즈 비율 (required)
- withReplacement: 중복 데이터 포함 여부 (required)
- seed: random seed 값 (optional)
- 입력 DataFrame의 유효성 검사를 진행한다. (fractionList, selected Columns)
- Spark RDD의 keyBy로 분류 한 후 sampleByKey 내장 함수를 실행한다.
- 출력 DataFrame을 생성한다.
| data1 |
data2 |
| 1 |
a |
| 1 |
b |
| 2 |
c |
| 2 |
d |
| 2 |
e |
| 3 |
f |
- (Key, value)는 (“1”, 0.1), (“2”, 0.6)으로 설정을 하였다.
key: key 이름,value:비율
- 1번 key는 0.1의 비율로 2번 key는 0.6의 비율로 설정을 하였기 때문에 위와 같은 결과 DataFrame을 얻을 수 있다.
- parameter는 다음과 같이 설정하였다.
val sampleStratifiedInfo = SampleStratifiedInfo.newBuilder()
.setSelectedColumnId(0)
.addFractions(
FractionFieldEntry.newBuilder()
.setKey("1")
.setValue(0.1)
.build())
.addFractions(
FractionFieldEntry.newBuilder()
.setKey("2")
.setValue(0.6)
.build())
.setWithReplacement(false)
.setSeed(7)
.build