- n개의 data를 k개의 cluster로 나누는 것을 목적으로 하고 있다.
- 입력 데이터 집합의 각 데이터들과 k개의 cluster 중심점과의 거리를 각각 구하고 각 data는 가장 유사도가 높은 중심점에 각 데이터를 할당하게 된다.
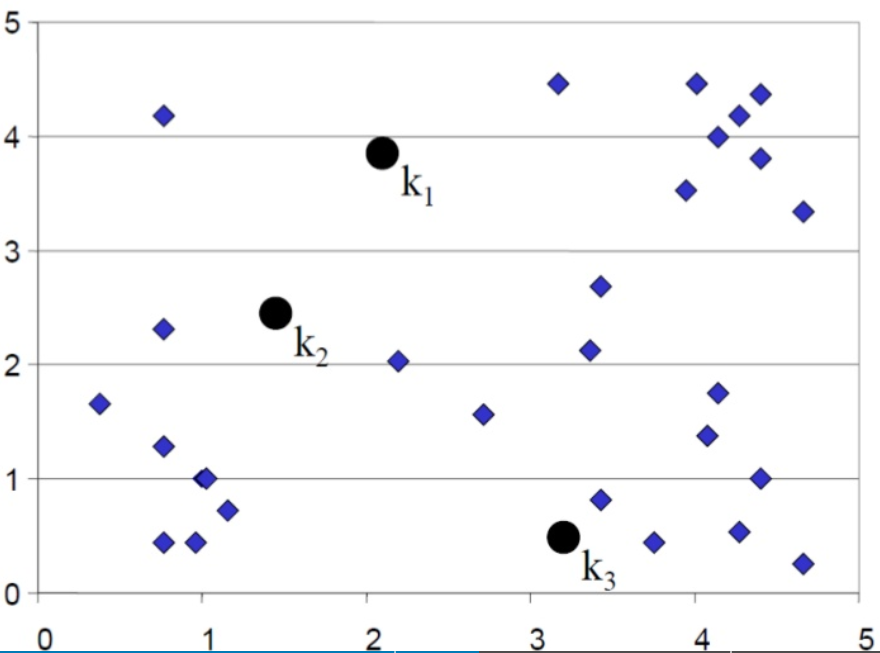
- 입력 데이터 집합에서 K(3)개의 데이터를 임의로 추출하고 이 데이터를 각 cluster의 중심으로 설정한다. 입력 데이터 집합의 각 데이터 들과 k개의 cluster 중심점과의 거리를 각각 구하고, 가장 유사도가 높은 중심점에 각 데이터를 할당하게 된다.
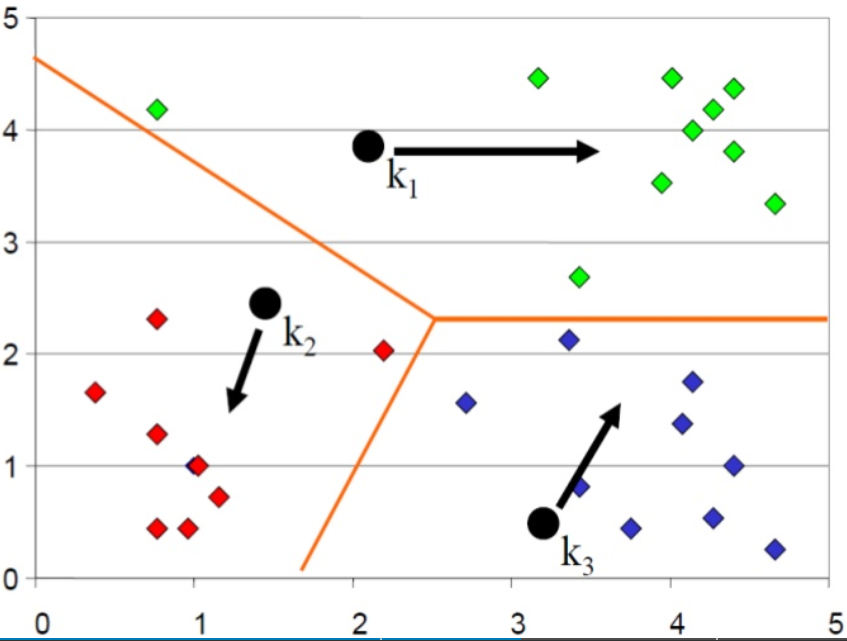
- 모두 할당하였으면 cluster의 중심점을 다시 계산한다.
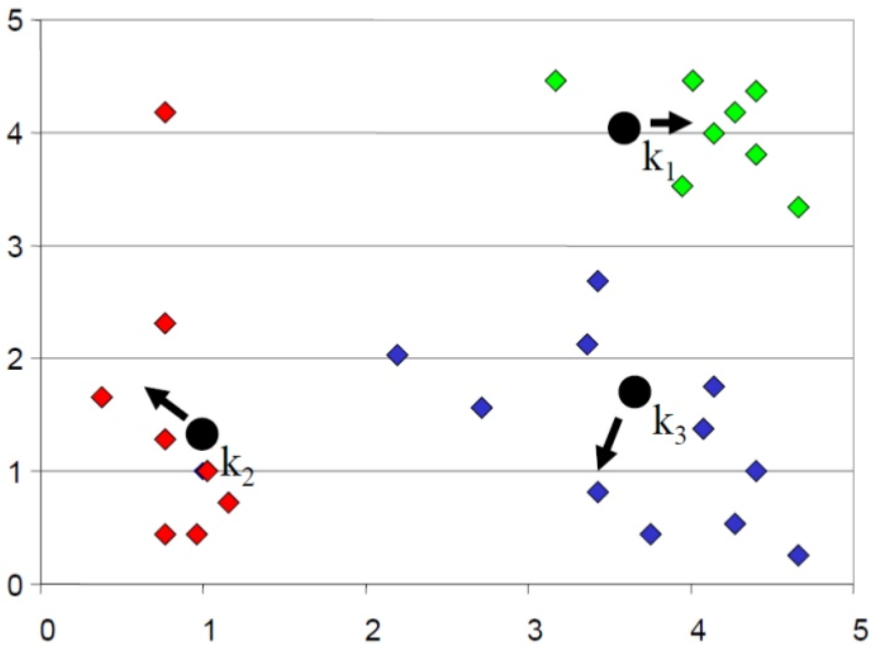
- cluster가 바뀌지 않을 때까지 반복적으로 거리계산 및 cluster 할당 작업을 수행을 하게 된다.
- k_value: cluster의 개수 (required)
- maxIterations: k-Means를 한번 수행할 때 수행되는 최대 반복 횟수. KMeans 시도 횟수 (required)
- maxRuns: 최적화된 임의 지점을 찾기 위한 시도 횟수 (optional)
- seed: random seed 값 (optional)
- 입력 DataFrame의 유효성 검사를 진행한다. (Numeric Columns)
- DataFrame을 Vectors로 변환한다.
- Spark ml의 KMeans 알고리즘을 실행한다.
- 출력 DataFrame을 생성한다.
| index |
data1 |
data2 |
data3 |
data4 |
data5 |
| 1 |
91.5775 |
81.572 |
84 |
73.2035 |
79.5918 |
| 2 |
83.4467 |
72.9477 |
92 |
60.6273 |
75.1917 |
| 3 |
47.0239 |
51.3076 |
31 |
25.807 |
36.0382 |
| 4 |
69.9559 |
61.0005 |
76 |
76.643 |
71.2145 |
| 5 |
57.2462 |
53.9258 |
79 |
65.2266 |
66.0508 |
| 6 |
42.8488 |
46.1728 |
7 |
31.9797 |
28.3842 |
| 7 |
73.7949 |
64.0751 |
98 |
61.2696 |
74.4483 |
| 8 |
22.4626 |
31.7166 |
6 |
28.549 |
22.0886 |
| index |
data1 |
data2 |
data3 |
data4 |
data5 |
CLUSTER |
| 1 |
91.5775 |
81.572 |
84 |
73.2035 |
79.5918 |
0 |
| 2 |
83.4467 |
72.9477 |
92 |
60.6273 |
75.1917 |
0 |
| 3 |
47.0239 |
51.3076 |
31 |
25.807 |
36.0382 |
1 |
| 4 |
69.9559 |
61.0005 |
76 |
76.643 |
71.2145 |
0 |
| 5 |
57.2462 |
53.9258 |
79 |
65.2266 |
66.0508 |
0 |
| 6 |
42.8488 |
46.1728 |
7 |
31.9797 |
28.3842 |
1 |
| 7 |
73.7949 |
64.0751 |
98 |
61.2696 |
74.4483 |
0 |
| 8 |
22.4626 |
31.7166 |
6 |
28.549 |
22.0886 |
1 |
- 결과 데이터의 CLUSTER column에서 각 data들이 할당된 cluster를 보여준다.
- K 값을 2로 설정하였으므로 위와 같이 2개의 cluster에 data들이 할당되는 것을 알 수 있다.
- parameter는 다음과 같이 설정 하였다.
val kMeansInfo = KMeansInfo.newBuilder()
.setKValue(2)
.setMaxIterations(100)
.setMaxRuns(10)
.setSeed(7)
.build