- 계층적 트리 모양을 이용해 개별 개체들을 순차적, 계층적으로 유사한 개체 그룹과 통합하여 군집화를 수행하는 알고리즘이다.
- 먼저 거리가 가장 가까운 것을 하나의 클러스터로 묶게 된다.

- 그 다음 또 다시 가장 가까운 것을 묶게 된다.

- 이런 식으로 모든 데이터가 하나로 묶을 때까지 반복 수행을 하게 된다.
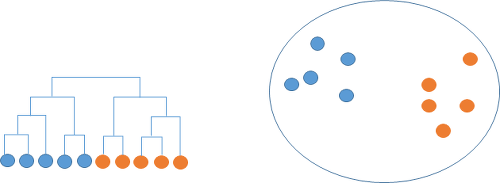
- 만약 2개의 클러스터로 나누고 싶다면 아래와 같이 할당하면 된다.
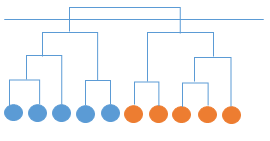
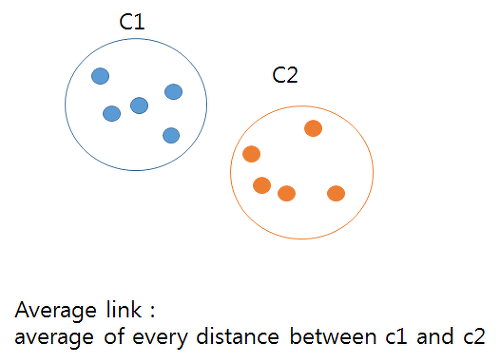
- 거리계산 할 때의 사용된 방법에는 Single link, Complete link, Average link 방식을 사용하게 된다.
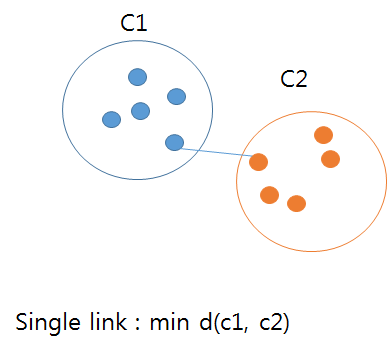
Single link 방식은 클러스터 간의 최소 거리로 측정하게 된다.
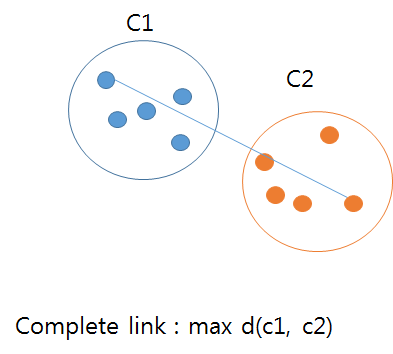
Complete link 방식은 클러스터 간의 최대 거리로 측정하게 된다.
Average link 방식은 모든 점과의 거리를 평균 내 측정하게 된다.
- numberOfClusters: cluster의 개수 (required)
- link: cluster 사이의 거리 측정 방식. Enum(SINGLE, COMPLETE, AVERAGE), (required)
- 입력 DataFrame의 유효성 검사를 진행한다. (cluster 개수, Numeric Columns)
- 변수 초기화를 한다. (remaining, clusterMap)
- 가장 거리가 가까운 것을 시작위치로 설정한다.
- 거리를 계산하여 근접한 cluster는 병합되어 하나의 cluster로 생성이 되어간다.
- cluster의 개수가 맞을 때까지 반복진행을 한다.
- 출력 DataFrame을 생성한다.
| data1 |
data2 |
data3 |
data4 |
data5 |
| 91.5775 |
81.572 |
84 |
73.2035 |
79.5918 |
| 83.4467 |
72.9477 |
92 |
60.6273 |
75.1917 |
| 47.0239 |
51.3076 |
31 |
25.807 |
36.0382 |
| 69.9559 |
61.0005 |
76 |
76.643 |
71.2145 |
| 57.2462 |
53.9258 |
79 |
65.2266 |
66.0508 |
| 42.8488 |
46.1728 |
7 |
31.9797 |
28.3842 |
| 73.7949 |
64.0751 |
98 |
61.2696 |
74.4483 |
| 22.4626 |
31.7166 |
6 |
28.549 |
22.0886 |
| data1 |
data2 |
data3 |
data4 |
data5 |
CLUSTER |
| 91.5775 |
81.572 |
84 |
73.2035 |
79.5918 |
2 |
| 83.4467 |
72.9477 |
92 |
60.6273 |
75.1917 |
2 |
| 47.0239 |
51.3076 |
31 |
25.807 |
36.0382 |
0 |
| 69.9559 |
61.0005 |
76 |
76.643 |
71.2145 |
1 |
| 57.2462 |
53.9258 |
79 |
65.2266 |
66.0508 |
1 |
| 42.8488 |
46.1728 |
7 |
31.9797 |
28.3842 |
0 |
| 73.7949 |
64.0751 |
98 |
61.2696 |
74.4483 |
2 |
| 22.4626 |
31.7166 |
6 |
28.549 |
22.0886 |
0 |
val agglomerativeClusteringInfo = AgglomerativeClusteringInfo.newBuilder()
.setNumberOfClusters(3)
.setLink(LinkType.SINGLE)
.build
- 거리 측정 방식은 SINGLE 방식(cluster 간의 최소 거리로 측정)으로 설정하였다.
- numberOfClusters를 3개로 설정해 주었으므로 3개의 cluster(0,1,2)에 data들이 할당되었음을 알 수 있다.