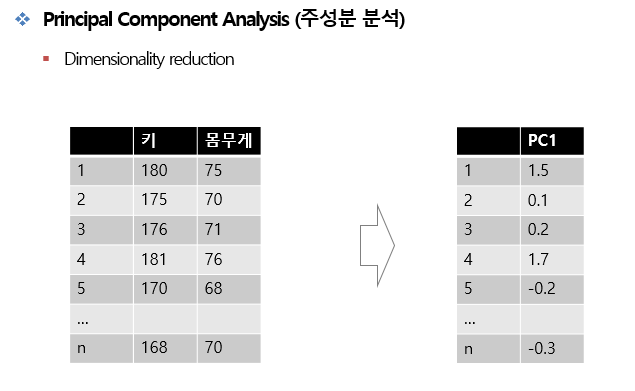
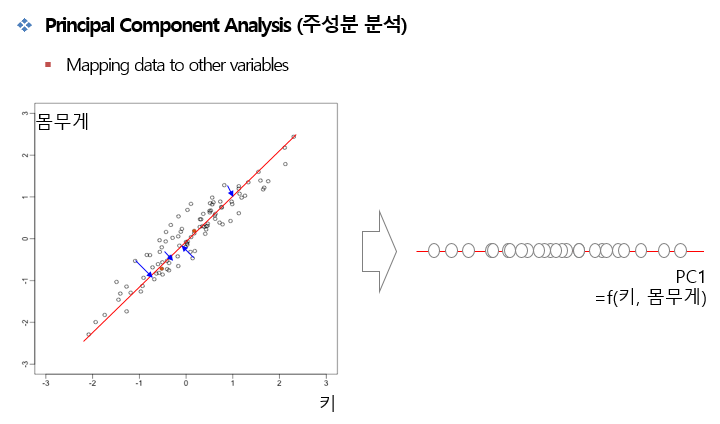
- 데이터의 분산(variance)을 최대한 보존하면서 서로 직교하는 새 축을 찾아, 고차원 공간의 표본들을 선형 연관성이 없는 저차원 공간으로 변환하는 기법이다.
- k_value: components의 개수 (required)
| data1 |
data2 |
data3 |
data4 |
| 5.1 |
3.5 |
1.4 |
0.2 |
| 4.9 |
3 |
1.4 |
0.2 |
| 4.7 |
3.2 |
1.3 |
0.2 |
| 4.6 |
3.1 |
1.5 |
0.2 |
| 5 |
3.6 |
1.4 |
0.2 |
| 5.4 |
3.9 |
1.7 |
0.4 |
| 4.6 |
3.4 |
1.4 |
0.3 |
| 5 |
3.4 |
1.5 |
0.2 |
| 4.4 |
2.9 |
1.4 |
0.2 |
| 4.9 |
3.1 |
1.5 |
0.1 |
| index |
pc1 |
pc2 |
| 1 |
-0.286 |
0.0469 |
| 2 |
0.2059 |
0.2269 |
| 3 |
0.2126 |
-0.0547 |
| 4 |
0.3182 |
-0.0373 |
| 5 |
-0.2908 |
-0.0879 |
| 6 |
-0.8452 |
-0.0168 |
| 7 |
0.1082 |
-0.2691 |
| 8 |
-0.1639 |
0.0524 |
| 9 |
0.6116 |
-0.0619 |
| 10 |
0.1292 |
0.2017 |
- K값은 추출할 주성분 개수이고 K값을 2로 설정하였다.
- 입력 DataFrame의 data들을 새로운 축 pc1, pc2에 표현 함으로써 4차원에서 2차원으로 차원이 축소 되었음을 확인할 수 있다.
- parameter는 다음과 같이 설정하였다.
val principalComponentAnalysisInfo =
PrincipalComponentAnalysisInfo.newBuilder()
.setKValue(2)
.build