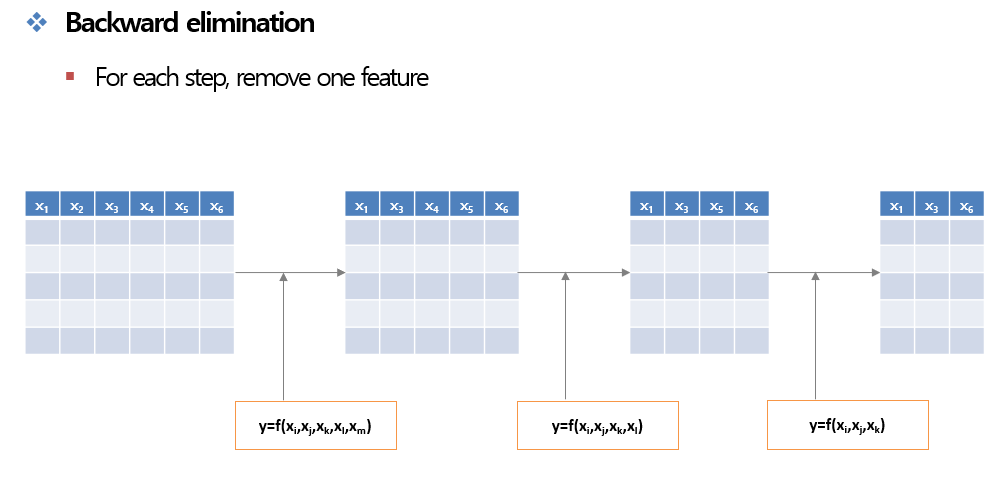
- 모든 설명 변수를 고려한 모형에서 유의하지 않은 설명 변수를 하나씩 제거하는 방법이다.
Spark ml의 LinearRegeression을 사용하여 P-Value를 구하여 유의성 검증 하게 된다. 입력 받은 기준 P-Value보다 클 경우 적합하지 않은 칼럼으로 제거 처리하도록 구현하였다.
- labelName: 라벨 이름 (required)
- pValue: 귀무가설이 맞다고 가정했을 때 해당 관측치와 그것보다 더 극단적인 관측치가 나올 확률 (required)
- 입력 DataFrame의 유효성 검사를 진행한다. (P-Value, Label Column, Numeric Column)
- 가장 적합하지 않은 칼럼을 가져온 후 제거 한다. (LinearRegeression을 사용하여 P-Value 구함)
- 2번 작업을 제거할 데이터가 없을 때까지 반복한다.
- 출력 DataFrame을 생성한다.
| label |
a1 |
a2 |
a3 |
a4 |
a5 |
| 88.01632464 |
0.636574028 |
8.442168148 |
2.116099574 |
2.771867529 |
8.448426549 |
| 138.7548543 |
4.595454155 |
4.388041662 |
4.926093835 |
2.682403955 |
8.617751819 |
| 38.28387155 |
4.292060076 |
0.861090232 |
9.15798394 |
6.607498138 |
4.084605081 |
| 82.14778398 |
8.559949469 |
3.856237673 |
1.0381353 |
1.687798024 |
2.8930632 |
| 33.79002054 |
2.272320698 |
1.834078721 |
6.300620501 |
1.93796937 |
2.069888374 |
| 7.38866956 |
3.956280442 |
0.34429275 |
4.337370526 |
7.563450458 |
8.591228627 |
| 191.4532705 |
2.220060635 |
7.843024669 |
6.462687043 |
8.731893832 |
9.28188111 |
| 15.34906002 |
6.105141656 |
1.074919676 |
1.162823303 |
9.241172289 |
7.23885872 |
| 97.40527838 |
2.691071171 |
3.571957641 |
7.805965771 |
6.843146634 |
3.053870888 |
| 111.4973958 |
4.262579387 |
7.369277727 |
0.820670523 |
6.687792013 |
3.976156809 |
| index |
label |
a2 |
| 1 |
88.01632464 |
8.442168148 |
| 2 |
138.7548543 |
4.388041662 |
| 3 |
38.28387155 |
0.861090232 |
| 4 |
82.14778398 |
3.856237673 |
| 5 |
33.79002054 |
1.834078721 |
| 6 |
7.38866956 |
0.34429275 |
| 7 |
191.4532705 |
7.843024669 |
| 8 |
15.34906002 |
1.074919676 |
| 9 |
97.40527838 |
3.571957641 |
| 10 |
111.4973958 |
7.369277727 |
- p-Value는 0.1로 설정하였다 (1%).
- Stepwise Backward Eliminate Operator는 모든 변수가 있는 상태에서 적합하지 않은 변수를 하나씩 하나씩 제거하는 것이다. 결과 DataFrame을 보면 a2 이외의 column들은 적합하지 않아 제거 되었음을 알 수 있다.