---
html:
toc: true
offline: true
export_on_save:
html: true
---
# Reader 컴퍼넌트 개발하기
---
Reader 컴퍼넌트을 만들기 위한 절차는 다음과 같습니다.
- 신규 컴퍼넌트용 Protocol Buffer 메세지 작성
- 새로 작성한 메세지를 포함한 프레임워크 코어 새로 빌드
- Reader 컴퍼넌트 스칼라 코드 작성
- 컴퍼넌트 빌드하여 프레임워크에 배포
아래에는 Reader 컴퍼넌트를 개발하고 이를 실행 중인 KSB 프레임워크 상에 배포하는 과정을 설명합니다. 자세한 설명을 위해서 파일을 읽어 DataFrame을 생성하는 간단한 Reader인 *MyFileReader* 개발을 대상으로 설명을 하도록 하겠습니다. 단, 이미 *MyFileReader*가 등록되어 있으므로, 여기서는 **MyFileReader**로 변경해서 신규 컴퍼넌트로 작성하여 등록하는 과정을 진행해 보도록 하겠습니다.
## 컴퍼넌트용 Protocol Buffer 메세지 작성
우선, 개발할 MyFileReader에 전달될 파라메터를 Google의 Protocol buffer 메세지 방식으로 작성해야 합니다. 이를 위해서 다운로드한 KSB 프레임워크 오픈소스를 ScalaIDE를 이용하여 프로젝트를 열어 **ksb-core-digest_2.11** 프로젝트가 있는지 확인합니다.
**ksb-core-digest_2.11** 모듈은 엔진을 생성하고 구동하기 위한 컴퍼넌트들의 파라메터를 정의한 Protocol buffer 메시지들을 모아놓은 모듈이며, 다음과 같은 구조를 같습니다.
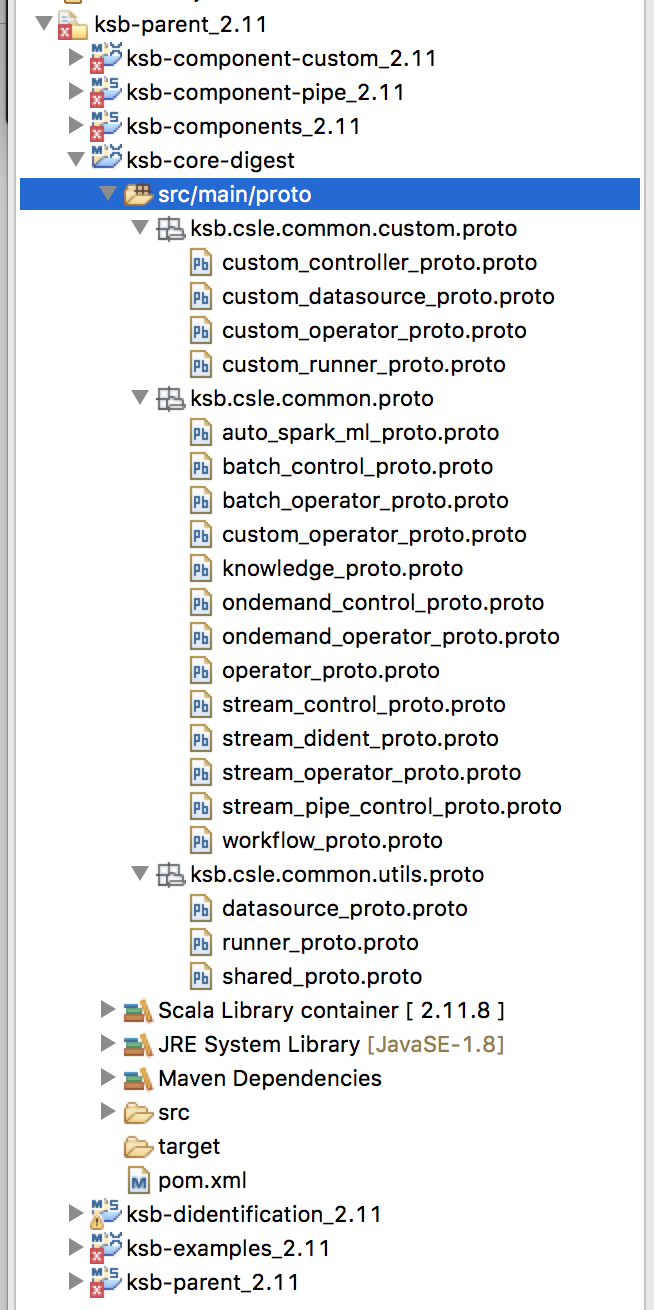 예제로 작성할 MyFileReader는 파일시스템으로부터 특정 경로의 파일을 읽어 DataFrame 형태의 데이터를 생성하는 컴퍼넌트입니다. ksb.csle.common.custom.proto 패키지 내에 있는 **custom_datasource_proto.proto** 파일을 열어 아래와 같이 **MyFileInfo** 메세지를 작성합니다.
```protobuf
message MyFileInfo {
repeated string filePath = 1;
optional FileType fileType = 2 [default = JSON];
optional string delimiter = 3 [default = ","];
repeated FieldInfo field = 4;
optional bool header = 5 [default = false];
optional SaveMode saveMode = 6 [default = OVERWRITE];
enum FileType {
CSV = 0;
JSON = 1;
PARQUET = 2;
TEXT = 3;
}
enum SaveMode {
APPEND = 0;
OVERWRITE = 1;
ERROR_IF_EXISTS = 2;
IGNORE = 3;
}
// Defines the schema of input data.
message FieldInfo {
required string key = 1;
required FieldType type = 2 [default=STRING];
optional string value = 3;
optional AttrType attrType = 4;
optional bool autoConfigured = 5 [default=true];
optional int32 nLevels = 6 [default = 5];
optional string filePath = 7;
enum AttrType {
IDENTIFIER = 0;
QUASIIDENTIFIER = 1;
SENSITIVE = 2;
NONSENSETIVE = 3;
}
enum FieldType {
STRING = 0;
INTEGER = 1;
DOUBLE = 2;
BOOLEAN = 3;
BYTE = 4;
FLOAT = 5;
LONG = 6;
TIMESTAMP = 7;
}
}
}
```
작성한 Protocol Buffer 메세지가 배치 처리용으로 사용될 예정이므로 **datasource_proto.proto** 내의 BatchReaderInfo 내에 oneof_operators 필드 내에 MySelectColumnsWithFileInfo 유형의 mySelectColumnsWithFile 필드로 등록합니다.
```protobuf
message BatchReaderInfo {
required int32 id = 1;
required int32 prevId = 2 [default = 0];
required string clsName = 4;
oneof oneof_readers {
MyFileInfo fileReader = 11;
TableInfo tableReader = 12;
PhoenixInfo phoenixReader = 14;
HttpServerInfo httpServerReader = 15;
MongodbInfo mongodbReader = 16;
MultipleReadersInfo multipleReaders = 50;
MyFileInfo myFileReader = 100;
}
}
```
## 새로운 프레임워크 코어 빌드하기
신규 컴퍼넌트를 추가하기 위해서는 본 페이지를 통해 신규 컴퍼넌트를 인식할 수 있도록 Core에 대한 바이너리를 신규로 빌드하여 사용해야 합니다.
**매뉴얼 > Core 빌드** 페이지로 이동합니다.
우리가 수정한 proto 파일(**datasource_proto.proto** ,**custom_datasource_proto.proto** )을 아래 그림과 같이 선택하고 빌드요청 버튼을 클릭합니다. 요청 후 약 20분 정도가 경과하면 자신의 로그인 계정의 메일로 신규 빌드된 core 바이너리가 도착합니다(참고: 요청은 순차적으로 처리되므로 미리 대기중인 요청이 있다면 20분 이상 걸릴 수 있음).
## 새로운 프레임워크 코어로 프로젝트 빌드하기
메일에서 바이너리를 다운로드한 후, 확장자를 .jar로 변경하고, KSB 개발 프로젝트 디렉토리의 최상위 디렉토리아래 libs 디렉토리 (ksb-oss_dist/libs)에 ksb-core_2.11-${project.version}-SNAPSHOT.jar 파일을 업데이트 합니다.
아래와 같이 Maven 명령을 실행하여 전체 프로젝트를 새로 빌드한다.
```sh
$ mvn generate-sources package install -P gpu -DskipTests -Drat.skip=true
```
## 신규 컴퍼넌트 스칼라 코드 작성
다음으로 작성된 메시지를 이용하여 신규컴퍼넌트 클래스를 개발합니다.
**ksb-components-custom_2.11** 모듈을 열어 아래와 같이 MyFileReader를 구현합니다. 이 Reader는 . BaseDataOperator 클래스의 정의에 따라 operate(df: DataFrame)를 반드시 override 해야 프레임워크 상에서 Controller에 의해 수행이 가능합니다. 자세한 사항은 KSB 프레임워크 Scala API를 참조하시기 바랍니다.
```scala
package ksb.csle.component.reader.custom
import scala.collection.JavaConversions._
import java.io._
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.types._
import ksb.csle.common.base.reader.BaseReader
import ksb.csle.common.utils.SparkUtils.getSchema
import ksb.csle.common.proto.DatasourceProto.BatchReaderInfo
import ksb.csle.common.proto.CustomDatasourceProto.MyFileInfo
import ksb.csle.common.proto.CustomDatasourceProto.MyFileInfo.FieldInfo
class MyFileReader(
val o: BatchReaderInfo
) extends BaseReader[DataFrame, BatchReaderInfo, SparkSession](o) {
private val myFileReaderInfo: MyFileInfo = o.getMyFileReader
// TODO: Adds all kinds of type casting.
def getSchema(ts: List[FieldInfo]): StructType =
StructType(
ts.map { t =>
t.getType match {
case FieldInfo.FieldType.INTEGER =>
StructField(t.getKey, IntegerType, true)
case FieldInfo.FieldType.STRING =>
StructField(t.getKey, StringType, true)
case FieldInfo.FieldType.DOUBLE =>
StructField(t.getKey, DoubleType, true)
case FieldInfo.FieldType.BOOLEAN =>
StructField(t.getKey, BooleanType, true)
case FieldInfo.FieldType.BYTE =>
StructField(t.getKey, ByteType, true)
case FieldInfo.FieldType.FLOAT =>
StructField(t.getKey, FloatType, true)
case FieldInfo.FieldType.LONG =>
StructField(t.getKey, LongType, true)
case FieldInfo.FieldType.TIMESTAMP =>
StructField(t.getKey, TimestampType, true)
case _ =>
StructField(t.getKey, StringType, true)
}
})
override def read(spark: SparkSession): DataFrame = {
import spark.implicits._
try {
logger.debug("Operation: MyFileReader")
if(myFileReaderInfo.getFileType.toString().toLowerCase() != "csv"){
if (myFileReaderInfo.getFieldList.toList.size() > 0) {
spark.sqlContext.read
.format(myFileReaderInfo.getFileType.toString().toLowerCase())
.option("header", myFileReaderInfo.getHeader()) // Use first line of all files as header
.option("sep", myFileReaderInfo.getDelimiter)
.schema(getSchema(myFileReaderInfo.getFieldList.toList))
.load(myFileReaderInfo.getFilePathList.toList.mkString(","))
}else{
spark.sqlContext.read
.format(myFileReaderInfo.getFileType.toString().toLowerCase())
.option("header", myFileReaderInfo.getHeader()) // Use first line of all files as header
.option("inferSchema", "true")
.option("sep", myFileReaderInfo.getDelimiter)
.load(myFileReaderInfo.getFilePathList.toList.mkString(","))
}
}else{
if (myFileReaderInfo.getFieldList.toList.size() > 0) {
spark.read
.option("header", myFileReaderInfo.getHeader())
.option("sep", myFileReaderInfo.getDelimiter)
.schema(getSchema(myFileReaderInfo.getFieldList.toList))
.csv(myFileReaderInfo.getFilePathList.toList.mkString(","))
}else{
spark.read
.option("header", myFileReaderInfo.getHeader())
.option("inferSchema", "true")
.option("sep", myFileReaderInfo.getDelimiter)
.csv(myFileReaderInfo.getFilePathList.toList.mkString(","))
}
}
} catch {
case e: ClassCastException =>
logger.error(s"Unsupported type cast error: ${e.getMessage}")
throw e
case e: UnsupportedOperationException =>
logger.error(s"Unsupported file reading error: ${e.getMessage}")
throw e
case e: Throwable =>
logger.error(s"Unknown file reading error: ${e.getMessage}")
throw e
}
}
override def close: Unit = ()
}
object MyFileReader {
def apply(o: BatchReaderInfo): MyFileReader = new MyFileReader(o)
}
```
## 새 컴퍼넌트 빌드하여 jar 파일 생성하기
작성한 스칼라 오퍼레이터 클래스를 빌드하여 새로운 .jar를 생성하기 위하여 component-custom 프로젝트 위치에서 maven 명령(아래)을 이용하여 새로운 오퍼레이터가 포함된 바이너리(jar)를 빌드합니다.
```sh
$ cd component-custom
$ mvn generate-sources package install -P gpu -DskipTests -Drat.skip=true
```
결과로 target 디렉토리에 **ksb-component-custom_2.11-{version}.jar** 가 생성된 것을 확인합니다.
## 새로운 컴퍼넌트를 실행 프레임워크에 배포
새로 작성한 메세제와 오퍼레이터가 포함된 바이너리를 KSB 프레임워크 실행바이너리가 있는 위치에 배포합니다. (레파지토리에 배포가 완료됨과 동시에 별도의 설치과정 없이 클라이언트의 요청 시 KSB 프레임워크에 의해 동적으로 클러스터 상의 노드들에 배포되어 엔진을 생성하고 구동하는데 적용이 됩니다.)
새로 배포해야할 KSB 프레임워크의 패키지는 아래와 같이 두 개의 jar에 해당합니다.
- ksb-csle/libs/**ksb-core_2.11-{version}.jar**
-- 신규메세지 포함된 core 바이너리로서 core 빌드 요청결과로 받은 파일
- ksb-csle/component-custom/target/**ksb-component-custom_2.11-{version}.jar**
-- 새로 작성한 컴퍼넌트 포함. 콘솔창에서 아래와 같이 maven 명령을 실행 위의 ksb-component-custom_2.11 빌드파일을 생성할 수 있습니다.
상기의 빌드된 패키지를 KSB 프레임워크 상에서 지정한 아카이브 디렉토리에 복사해서 넣어줌으로써 배포가 완료가 완료됩니다.
참고로, 아카이브 위치는 별도의 설정이 없다면 내부적으로 ```${KSB_HOME}/jars/${ksb-vsersion}``` 디렉토리를 기본값으로 사용합니다.
예제로 작성할 MyFileReader는 파일시스템으로부터 특정 경로의 파일을 읽어 DataFrame 형태의 데이터를 생성하는 컴퍼넌트입니다. ksb.csle.common.custom.proto 패키지 내에 있는 **custom_datasource_proto.proto** 파일을 열어 아래와 같이 **MyFileInfo** 메세지를 작성합니다.
```protobuf
message MyFileInfo {
repeated string filePath = 1;
optional FileType fileType = 2 [default = JSON];
optional string delimiter = 3 [default = ","];
repeated FieldInfo field = 4;
optional bool header = 5 [default = false];
optional SaveMode saveMode = 6 [default = OVERWRITE];
enum FileType {
CSV = 0;
JSON = 1;
PARQUET = 2;
TEXT = 3;
}
enum SaveMode {
APPEND = 0;
OVERWRITE = 1;
ERROR_IF_EXISTS = 2;
IGNORE = 3;
}
// Defines the schema of input data.
message FieldInfo {
required string key = 1;
required FieldType type = 2 [default=STRING];
optional string value = 3;
optional AttrType attrType = 4;
optional bool autoConfigured = 5 [default=true];
optional int32 nLevels = 6 [default = 5];
optional string filePath = 7;
enum AttrType {
IDENTIFIER = 0;
QUASIIDENTIFIER = 1;
SENSITIVE = 2;
NONSENSETIVE = 3;
}
enum FieldType {
STRING = 0;
INTEGER = 1;
DOUBLE = 2;
BOOLEAN = 3;
BYTE = 4;
FLOAT = 5;
LONG = 6;
TIMESTAMP = 7;
}
}
}
```
작성한 Protocol Buffer 메세지가 배치 처리용으로 사용될 예정이므로 **datasource_proto.proto** 내의 BatchReaderInfo 내에 oneof_operators 필드 내에 MySelectColumnsWithFileInfo 유형의 mySelectColumnsWithFile 필드로 등록합니다.
```protobuf
message BatchReaderInfo {
required int32 id = 1;
required int32 prevId = 2 [default = 0];
required string clsName = 4;
oneof oneof_readers {
MyFileInfo fileReader = 11;
TableInfo tableReader = 12;
PhoenixInfo phoenixReader = 14;
HttpServerInfo httpServerReader = 15;
MongodbInfo mongodbReader = 16;
MultipleReadersInfo multipleReaders = 50;
MyFileInfo myFileReader = 100;
}
}
```
## 새로운 프레임워크 코어 빌드하기
신규 컴퍼넌트를 추가하기 위해서는 본 페이지를 통해 신규 컴퍼넌트를 인식할 수 있도록 Core에 대한 바이너리를 신규로 빌드하여 사용해야 합니다.
**매뉴얼 > Core 빌드** 페이지로 이동합니다.
우리가 수정한 proto 파일(**datasource_proto.proto** ,**custom_datasource_proto.proto** )을 아래 그림과 같이 선택하고 빌드요청 버튼을 클릭합니다. 요청 후 약 20분 정도가 경과하면 자신의 로그인 계정의 메일로 신규 빌드된 core 바이너리가 도착합니다(참고: 요청은 순차적으로 처리되므로 미리 대기중인 요청이 있다면 20분 이상 걸릴 수 있음).
## 새로운 프레임워크 코어로 프로젝트 빌드하기
메일에서 바이너리를 다운로드한 후, 확장자를 .jar로 변경하고, KSB 개발 프로젝트 디렉토리의 최상위 디렉토리아래 libs 디렉토리 (ksb-oss_dist/libs)에 ksb-core_2.11-${project.version}-SNAPSHOT.jar 파일을 업데이트 합니다.
아래와 같이 Maven 명령을 실행하여 전체 프로젝트를 새로 빌드한다.
```sh
$ mvn generate-sources package install -P gpu -DskipTests -Drat.skip=true
```
## 신규 컴퍼넌트 스칼라 코드 작성
다음으로 작성된 메시지를 이용하여 신규컴퍼넌트 클래스를 개발합니다.
**ksb-components-custom_2.11** 모듈을 열어 아래와 같이 MyFileReader를 구현합니다. 이 Reader는 . BaseDataOperator 클래스의 정의에 따라 operate(df: DataFrame)를 반드시 override 해야 프레임워크 상에서 Controller에 의해 수행이 가능합니다. 자세한 사항은 KSB 프레임워크 Scala API를 참조하시기 바랍니다.
```scala
package ksb.csle.component.reader.custom
import scala.collection.JavaConversions._
import java.io._
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.types._
import ksb.csle.common.base.reader.BaseReader
import ksb.csle.common.utils.SparkUtils.getSchema
import ksb.csle.common.proto.DatasourceProto.BatchReaderInfo
import ksb.csle.common.proto.CustomDatasourceProto.MyFileInfo
import ksb.csle.common.proto.CustomDatasourceProto.MyFileInfo.FieldInfo
class MyFileReader(
val o: BatchReaderInfo
) extends BaseReader[DataFrame, BatchReaderInfo, SparkSession](o) {
private val myFileReaderInfo: MyFileInfo = o.getMyFileReader
// TODO: Adds all kinds of type casting.
def getSchema(ts: List[FieldInfo]): StructType =
StructType(
ts.map { t =>
t.getType match {
case FieldInfo.FieldType.INTEGER =>
StructField(t.getKey, IntegerType, true)
case FieldInfo.FieldType.STRING =>
StructField(t.getKey, StringType, true)
case FieldInfo.FieldType.DOUBLE =>
StructField(t.getKey, DoubleType, true)
case FieldInfo.FieldType.BOOLEAN =>
StructField(t.getKey, BooleanType, true)
case FieldInfo.FieldType.BYTE =>
StructField(t.getKey, ByteType, true)
case FieldInfo.FieldType.FLOAT =>
StructField(t.getKey, FloatType, true)
case FieldInfo.FieldType.LONG =>
StructField(t.getKey, LongType, true)
case FieldInfo.FieldType.TIMESTAMP =>
StructField(t.getKey, TimestampType, true)
case _ =>
StructField(t.getKey, StringType, true)
}
})
override def read(spark: SparkSession): DataFrame = {
import spark.implicits._
try {
logger.debug("Operation: MyFileReader")
if(myFileReaderInfo.getFileType.toString().toLowerCase() != "csv"){
if (myFileReaderInfo.getFieldList.toList.size() > 0) {
spark.sqlContext.read
.format(myFileReaderInfo.getFileType.toString().toLowerCase())
.option("header", myFileReaderInfo.getHeader()) // Use first line of all files as header
.option("sep", myFileReaderInfo.getDelimiter)
.schema(getSchema(myFileReaderInfo.getFieldList.toList))
.load(myFileReaderInfo.getFilePathList.toList.mkString(","))
}else{
spark.sqlContext.read
.format(myFileReaderInfo.getFileType.toString().toLowerCase())
.option("header", myFileReaderInfo.getHeader()) // Use first line of all files as header
.option("inferSchema", "true")
.option("sep", myFileReaderInfo.getDelimiter)
.load(myFileReaderInfo.getFilePathList.toList.mkString(","))
}
}else{
if (myFileReaderInfo.getFieldList.toList.size() > 0) {
spark.read
.option("header", myFileReaderInfo.getHeader())
.option("sep", myFileReaderInfo.getDelimiter)
.schema(getSchema(myFileReaderInfo.getFieldList.toList))
.csv(myFileReaderInfo.getFilePathList.toList.mkString(","))
}else{
spark.read
.option("header", myFileReaderInfo.getHeader())
.option("inferSchema", "true")
.option("sep", myFileReaderInfo.getDelimiter)
.csv(myFileReaderInfo.getFilePathList.toList.mkString(","))
}
}
} catch {
case e: ClassCastException =>
logger.error(s"Unsupported type cast error: ${e.getMessage}")
throw e
case e: UnsupportedOperationException =>
logger.error(s"Unsupported file reading error: ${e.getMessage}")
throw e
case e: Throwable =>
logger.error(s"Unknown file reading error: ${e.getMessage}")
throw e
}
}
override def close: Unit = ()
}
object MyFileReader {
def apply(o: BatchReaderInfo): MyFileReader = new MyFileReader(o)
}
```
## 새 컴퍼넌트 빌드하여 jar 파일 생성하기
작성한 스칼라 오퍼레이터 클래스를 빌드하여 새로운 .jar를 생성하기 위하여 component-custom 프로젝트 위치에서 maven 명령(아래)을 이용하여 새로운 오퍼레이터가 포함된 바이너리(jar)를 빌드합니다.
```sh
$ cd component-custom
$ mvn generate-sources package install -P gpu -DskipTests -Drat.skip=true
```
결과로 target 디렉토리에 **ksb-component-custom_2.11-{version}.jar** 가 생성된 것을 확인합니다.
## 새로운 컴퍼넌트를 실행 프레임워크에 배포
새로 작성한 메세제와 오퍼레이터가 포함된 바이너리를 KSB 프레임워크 실행바이너리가 있는 위치에 배포합니다. (레파지토리에 배포가 완료됨과 동시에 별도의 설치과정 없이 클라이언트의 요청 시 KSB 프레임워크에 의해 동적으로 클러스터 상의 노드들에 배포되어 엔진을 생성하고 구동하는데 적용이 됩니다.)
새로 배포해야할 KSB 프레임워크의 패키지는 아래와 같이 두 개의 jar에 해당합니다.
- ksb-csle/libs/**ksb-core_2.11-{version}.jar**
-- 신규메세지 포함된 core 바이너리로서 core 빌드 요청결과로 받은 파일
- ksb-csle/component-custom/target/**ksb-component-custom_2.11-{version}.jar**
-- 새로 작성한 컴퍼넌트 포함. 콘솔창에서 아래와 같이 maven 명령을 실행 위의 ksb-component-custom_2.11 빌드파일을 생성할 수 있습니다.
상기의 빌드된 패키지를 KSB 프레임워크 상에서 지정한 아카이브 디렉토리에 복사해서 넣어줌으로써 배포가 완료가 완료됩니다.
참고로, 아카이브 위치는 별도의 설정이 없다면 내부적으로 ```${KSB_HOME}/jars/${ksb-vsersion}``` 디렉토리를 기본값으로 사용합니다.